
|
July 2016 |
[an error occurred while processing this directive] |
| The Strategy
and Payoffs of Meta-Data Tagging Value creation is happening in the buildings industry as systems integrators transition to an open, industry-standard methodology for meta-data tagging and data modeling. |
B. Scott Muench, Vice President of Marketing & Business Development J2 Innovations |
| Articles |
| Interviews |
| Releases |
| New Products |
| Reviews |
| [an error occurred while processing this directive] |
| Editorial |
| Events |
| Sponsors |
| Site Search |
| Newsletters |
| [an error occurred while processing this directive] |
| Archives |
| Past Issues |
| Home |
| Editors |
| eDucation |
| [an error occurred while processing this directive] |
| Training |
| Links |
| Software |
| Subscribe |
| [an error occurred while processing this directive] |
The BAS industry is reworking how data is leveraged across the entire design-construction- operations cycle; new applications that use tagged data are being introduced at an accelerated rate; and building owner customers are reaping financial rewards across familiar activities and through new services. How much and how fast? Metcalfe’s Law is one way to predict the gains.
This observed rule of technology market behavior holds that the value of a network increases in proportion to the square of the number of connections. As more building owners start realizing all the benefits of self-describing data, there will be a bandwagon effect. The wider buildings industry will get on board and there will be even more application development activity spurring even greater potential paybacks for effectively tagged data. However, Metcalfe’s Law doesn’t tell the whole story. Here is my theory:
In other words, if the amount of effort it takes to tag
the thousands of automation system points maintained in historical
trend databases is too great, it will take a lot longer to realize
value from a data modeling project. This is why J2 Innovations has been
focusing its efforts on great software and more
efficient workflows.
Adding Meaning to Data
Traditionally, system integrators are responsible for defining
automation system points; yet, few of these professionals have ever
wrangled with data semantics, meta data tagging and taxonomies. Most
have specialized in working on a single brand of building automation
system (BAS) and have never encountered the issues that arise when you
try to combine data from different sources and bring it into
value-added applications. One global facilities management firm audited
the many databases storing trend data for building operations and
maintenance, and it discovered that it had about 1200 different ways to
name a light. With Project-Haystack methodology and the right tools for
automating the meta-tagging process, systematic tagging and data
modeling can be a straightforward job, even for a very large data set
like this. Will the payoffs be worth the effort? Many times over.
Counting the Payoffs
One of the most popular implementations of open-source Project Haystack
is nHaystack. This module enables Tridium Niagara stations (JACE and
WebSupervisor) to serve Haystack data via a RESTful protocol. Using
nHaystack, applications receive data complete with essential meta data
descriptors.
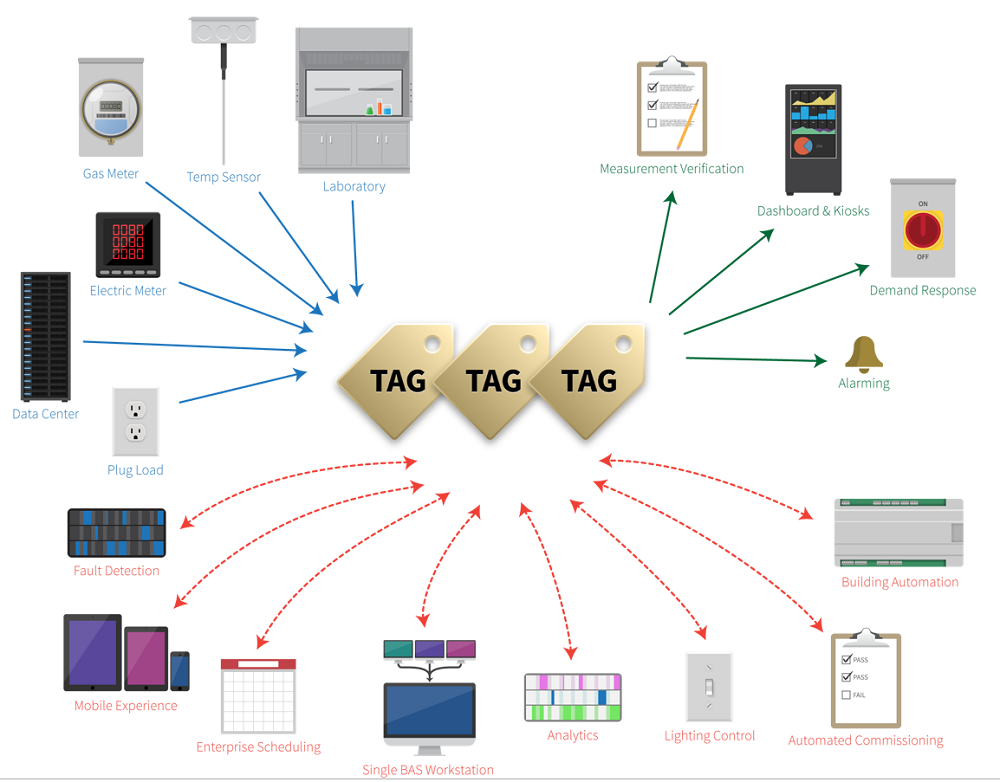
With a Haystack-tagged system, you can define tags once and realize value over and over again. nHaystack makes it easier for system integrators to add meaning to the Java-based Niagara component model. There are numerous other implementations being worked on by the Project-Haystack community too. For example, there are groups working in C++ and DART. All share the common goal of making it easier to unlock value from the vast quantity of data being generated by the smart devices that permeate our homes, buildings, factories, and cities. They realize that the way forward starts with defining tags for all the most common types of components and uses. The resulting self-describing models will pay off at the device, equipment and building-levels, as well as when they are shared by various applications for visualization, control, fault detection, analytics, maintenance ticketing, room scheduling, etc. (Figure 1)
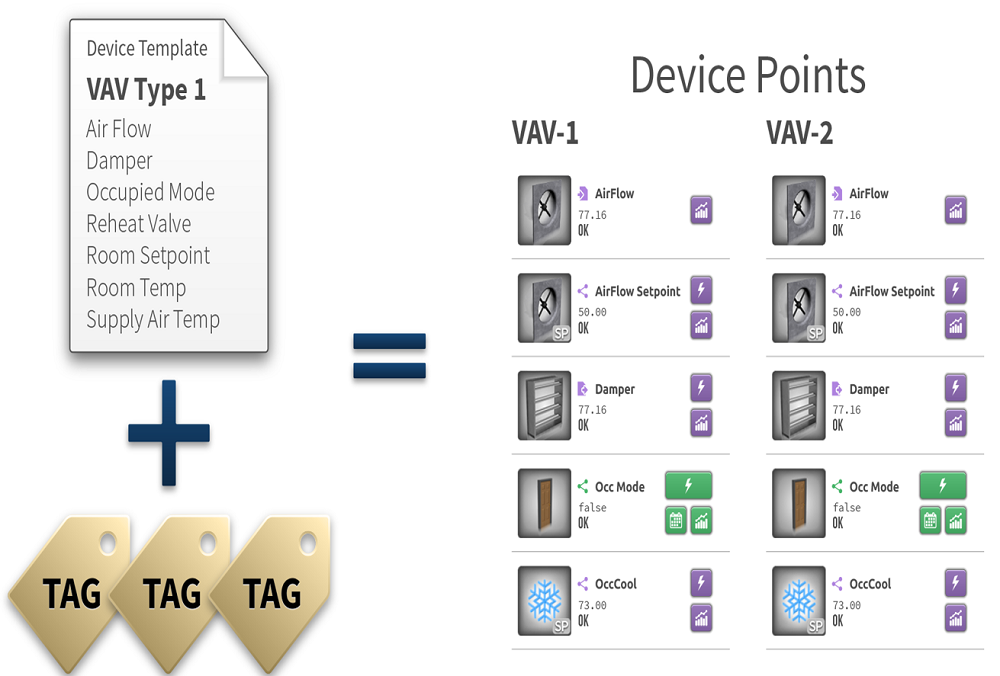
To illustrate, consider how a standard VAV for an air handler would be defined in Haystack. You would start with a device template that associates the points with all the standard attributes: air flow, supply air temperature, damper position, set point.
Payoff #1: There is great value in just having this device-level information model at hand when diagnosing a problem. For example, when an occupant calls to report ‘It’s too cold in this room,’ the points graphic would display in a normalized way the live values, independent of how they were defined and named at the control system level. With this knowledge, such situations can be easily and quickly diagnosed and addressed, often without a costly truck roll.
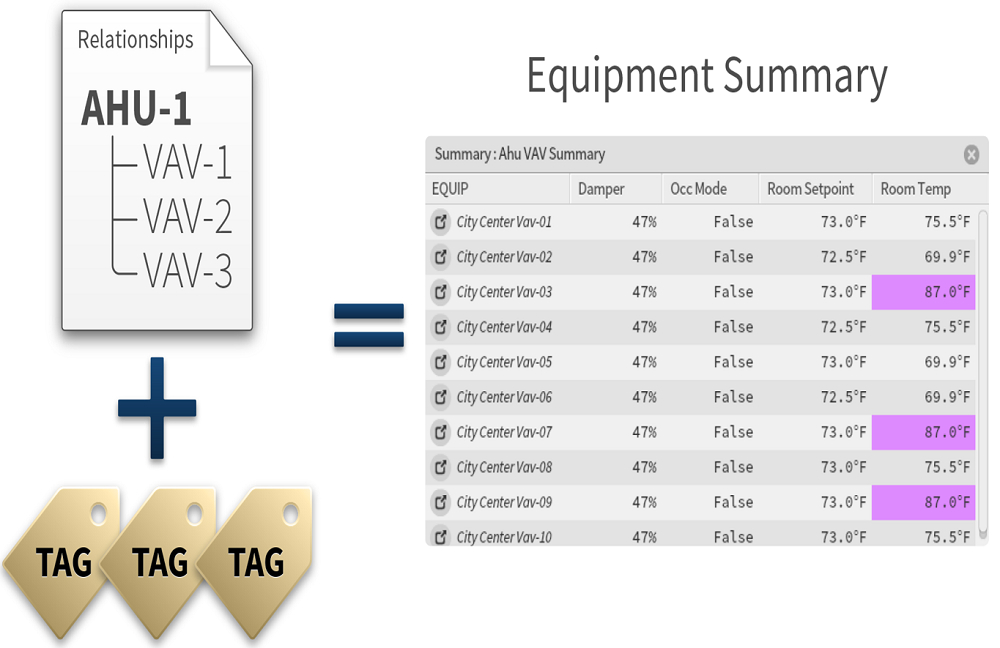
Payoff #2: Tags that reflect relationships are also useful, for instance how devices interrelate as part of a larger system. Relationship, or reference, tags can also represent dependencies of equipment to floors, floors to buildings, buildings to enterprise, etc. For example, reference tags can be used to build the hierarchical relationships of all the VAV’s in a particular air handler system. This makes it possible to call up equipment summaries. Anomalies are particularly easy to spot when they are presented in context of other similar devices.
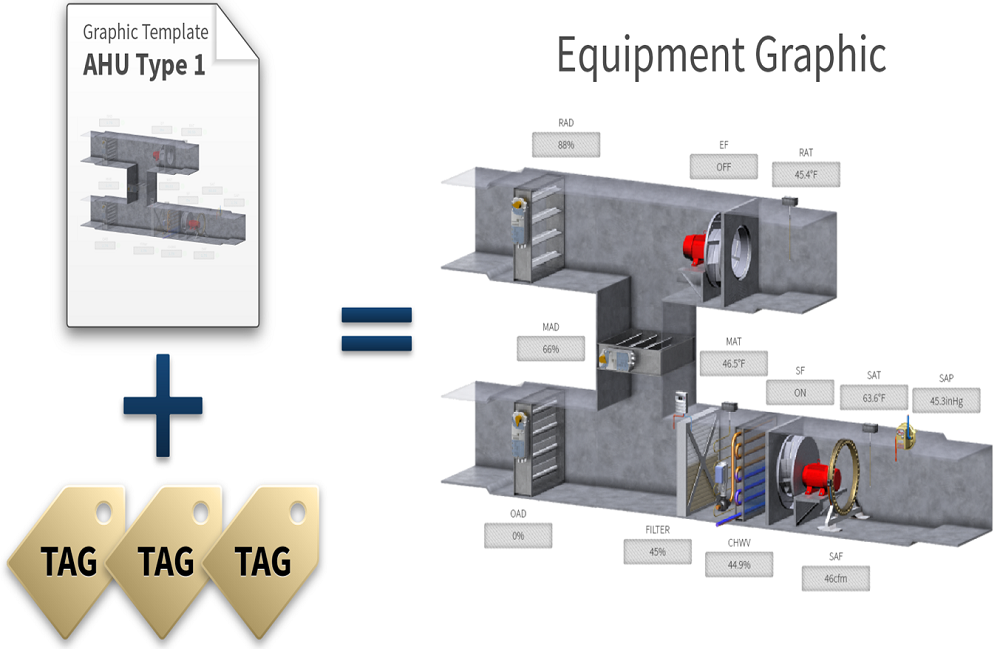
Payoff #3: Once you have built a set of self-describing models according to the standard Haystack methodology, you are in a good position to apply Haystack-compliant value-add applications that automatically plug the relevant operational data into the right place. The resulting app provides a user experience for navigation, point graphics, summary graphics, schedules, histories, alarms—in effect, all the information captured in the models delivered to any device anywhere. Clear, non-ambiguous information can go a long way toward simplifying the jobs of maintenance staff and facilities managers which is another way your investment in data modeling will pay back.
Payoff
#4: The return on investment increases when auto-control
functions enabled by a tagged and modeled system come into play. For
example, many building operators have the opportunity to save
significant energy costs through participation in demand-response
programs. However, orchestrating whole-building responsiveness given
all the data silos maintained by particular types of equipment and
subsystems (HVAC, lighting, enterprise scheduling) has been difficult
and costly to implement. By using the Haystack method, you can simply
tag models for all of the equipment that needs to be controlled and tag
the corresponding control sequence and it will ‘just work.’ This drastically
reduces the traditional amount of time, labor and cost required to
implement control strategies across the building.
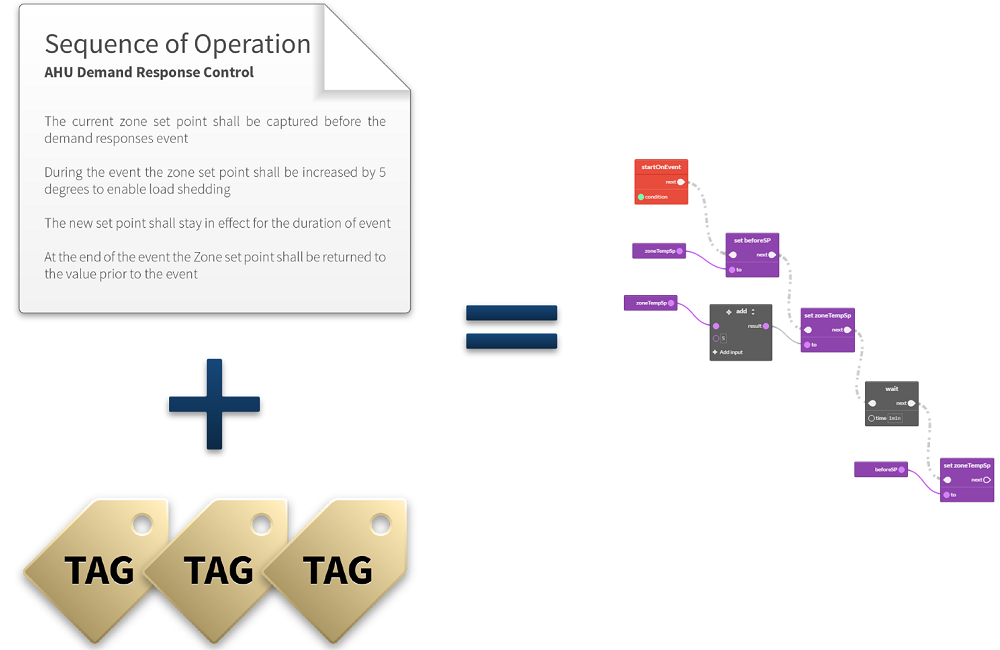
Payoff #5: Even more value is derived from an investment in a well-designed and deployed tagging and data modeling strategy when you apply analytics software for automatically analyzing building, energy and equipment data. Data analytics creates value by detecting patterns that represent opportunities for improved performance and cost savings. Automated analytics software will identify issues, patterns, deviations, faults and opportunities at the device, equipment and whole-building levels. Fast action to correct problems and optimize the delivery of building services reduces energy bills and contributes to the type of well-run facility that keeps occupants productive and satisfied with their space.

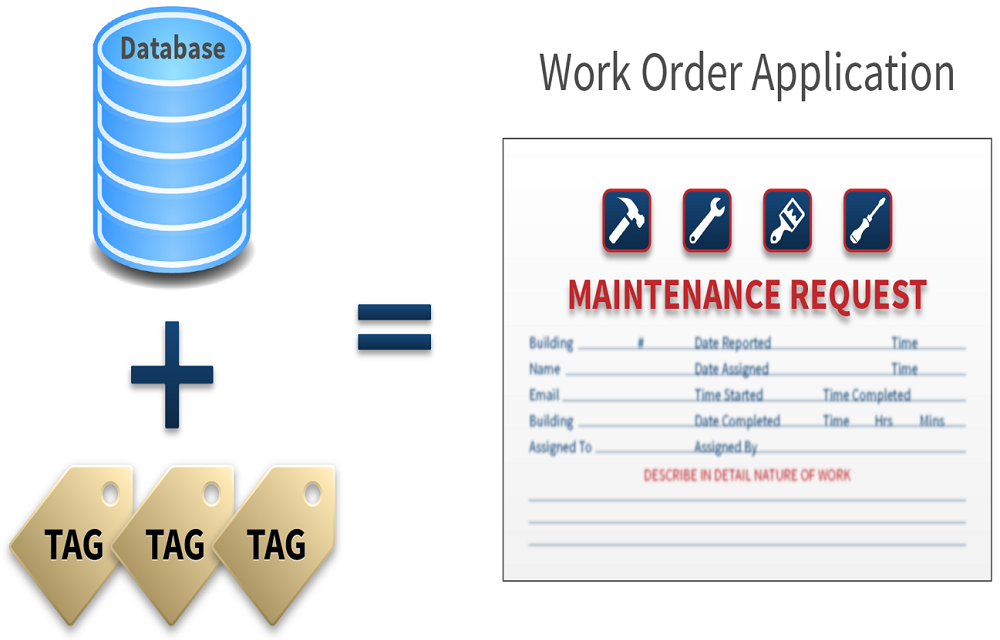
Payoff #6: You can also tag models for better integration of follow-through activities, like issuing maintenance tickets. Likewise, the way all building data is structured in a Haystack-compliant database means easier integration of building operations with other aspects of workplace management in an enterprise setting. Integrating building management within the larger IT infrastructure leads to additional cumulative benefits felt from the C-suite level to every member of the Operations & Maintenance staff.
Merging Legacy and
New IoT Workflows
The FIN Framework™ application suite incorporates a unified
toolset that makes it easy to do Haystack tagging and data modeling. It
enables optimized workflows to perform actions in batch using queries
to access data. Users can easily convert the data from all their
non-Haystack legacy global and field controllers to Haystack-able
models.
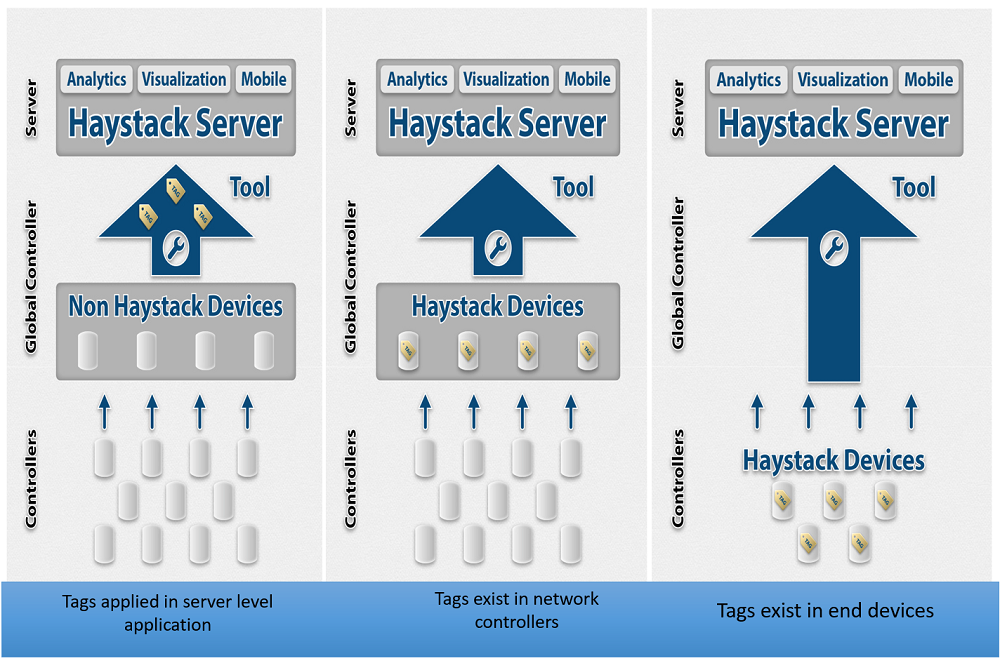
In this way, they manage server-level conversion of data flows. New Building IoT workflows can be added via edge control devices that already incorporate FIN technology for data tagging, such as the KMC Commander™ Series. Users maintain the ability to work across the entire portfolio as they deploy their applications. While early Building IoT workflows incorporate Haystack technology at the network- or global-controller level, soon it will be more commonplace to have edge devices pre-built with Haystack control.
Eventually, requirements will be written into
specifications to the effect that all vendors of equipment, meters,
other building-connected devices and software adhere to standard
tagging and modeling conventions. Every device or piece of software
will be delivered with a zip file containing Haystack-compliant data
models.
Summary
With software that leverages tagging and data modeling, we are
beginning to greatly reduce the number of mouse clicks required to
implement a solution. Following Muench’s Corollary to Metcalfe’s Law,
this streamlining of the user experience is unlocking the true value of
a connected system. Participation in Project Haystack is giving
property managers, building owners and system integrators a big head
start in the establishment of an in-house point taxonomy. They can then
enforce vendor specifications that call for
standardized tagging and data modeling across a portfolio and for all
aspects of building operations. Project Haystack is supported by an
active and growing open-source community of developers who are
collaborating on improving its definitions and modeling methodology.
For all these reasons, it is the most future-proof approach to
monetizing your building data.
[an error occurred while processing this directive]
[Click Banner To Learn More]
[Home Page] [The Automator] [About] [Subscribe ] [Contact Us]